一、Web搜索介绍
前面我们都是对传统文档集进行检索,而Web搜索和传统的搜索完全不同,因为Web的文档集数量是不能估计的,并且形式多样;
一般Web都是通过B/S架构进行实现的,客户端是浏览器,服务器端是web服务器,通过HTTP进行传输数据;
浏览器发出请求并接收服务器的应答,浏览器会自动屏蔽那些不能理解的部分;
Web的文档集是海量的,但是如果这些信息不能被搜索到的话,则这些信息是无用的,因此Web搜索很重要。
Web搜索的文档集不仅要相关,而且要注重权威;
可能会遇到的问题是有些网页是由图片组成的,没有文本文字;
静态页面:固定页面;
动态页面:与数据库交互的页面;
Web网页集可以转化成一张图,节点表示网页,边表示链接;
注意:Web图可能不是强连通的,即A节点可能不能够到达B节点;
入度为i的网页数目正比于1/(i^a);
为了让用户体验更好,一般需要:
(1)让搜索界面做的简洁,搜索出的网页也需要尽量简洁;
(2)相关度尽量高;
用户查询类型
(1)信息类查询:查相关主题的页面;
(2)导航类查询:查某个词的官方主页;
(3)事务类查询:需要干一件事,比如下载;
二、网页
网页的主要原因是经济利益;
1.在网页上充满重复的关键字以提高排名
2.将重复关键字作为背景色,使得用户看不出,但是会被搜索引擎构建索引
3.付费收录(Paid Inclusion):付钱给IR公司让他的网页排名靠前
4.伪装(Cloaking):spider爬到的网页和用户浏览器访问的网页不一致,比如采集器采集时返回相关文档,但是用户访问时却给出另一个网页;
5.桥页(doorway page):用户-->桥页-->商业网页;桥页是相关的,但是如果访问桥页,则直接跳转到另一个网页;
三、赞助搜索
Sponsored search
在网页中,右半部分是提供给赞助商的,赞助商给的钱越多,排名越靠前;
一般采用CPC(Cost Per Click)收费,用户点击一次,则赞助商付给IR公司一笔钱;
有些人利用垃圾点击(Click Spam),让赞助商多付钱给IR公司;
四、索引规模比较
注意:
1.搜索引擎会搜索到没有被索引的网页;
2.搜索引擎不会返回所有的索引页面;
因此很难精确估计索引规模;
注意:可能搜索引擎采集页面时会进入一个陷阱服务器,即只要访问了这个服务器,则服务器会自动生成无数网页让采集器采集;
比较两个搜索引擎的索引规模
给定两个搜索引擎E1和E2,我们采用随机在E1和E2中抽取网页,并比较E2抽出的网页在E1中出现的比例,E1抽出的网页在E2中出现的比例;
比如:
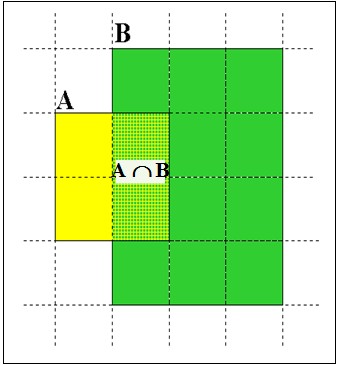
E1/E2=y/x=(1/6)/(1/2)=1/3;因此E1索引规模较少;
y表示E1的网页在E2中的比例;
x表示E2的网页在E1中的比例;
五、随机网页抽样方法
在前面我们采用随机抽网页的方式进行估计搜索引擎的索引规模,但是不可能做到随机抽样,因此我们采用一些随机抽样的技术:
(1)随机搜索法(Random Search):跟踪一个用户的查询记录,并从查询结果中随机抽取网页;
(2)随机IP地址法(Random IP Address):随机生成一个IP地址并对应的服务器,收集该服务器的所有网页;
(3)随机走路法(Random Walk):如果Web是强连通的,则可以发现一个规律;
(4)随机查询法(Random Query):随机生成一个查询提交给E1,然后从结果中抽取一个网页,并从网页中随机抽取6-8个低频词,放在E2中查询;
六、近似重复
在Web中有40%的网页都是重复的,有些是完全重复,有些是近似重复,比如创建日期不同,但内容相同;
搜索引擎需要避免索引重复的页面;
对于完全重复的网页检测,可以通过每个网页生成一个指纹进行比较;
Shingling:解决近似重复的方法
文档D的k-shingle是类似于K-gram的概念,表示K个连续的词项构成的序列,比如a Hello World a Hello world的3-shingle是a Hello world ,Hello World a ,World a Hello;
方法1:利用Jaccard系数计算两篇文档的相似度;但是计算太复杂;
方法2:
我们可以通过随机置换方法进行:
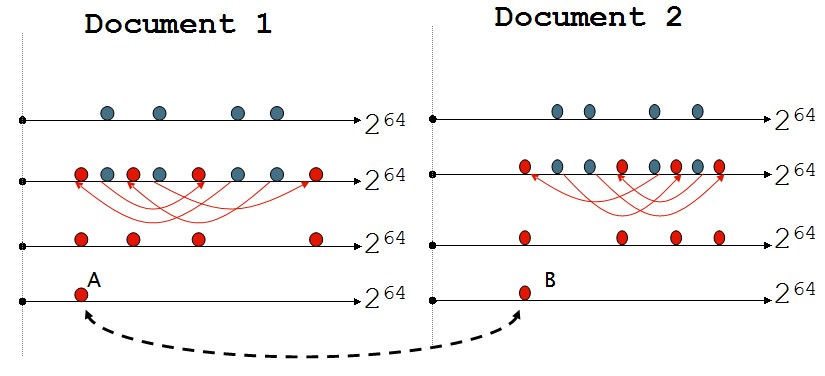
步骤:
(1)对于每篇文档的每个k-shingle通过Hash函数进行映射成为一个点,如上图第一行的蓝点;
(2)将这些点随机置换到新的位置,比如上图的红点;
(3)保留随机置换的点的最小点,取红点的最小点;
(4)当两篇文档最后保留的点位置一样时,则说明文档近似重复;
分享到:





相关推荐
文档内容清晰,排版整齐,包含题目与答案,适用于正在学习信息检索导论这门课程的学生,用于掌握重点与查漏补缺,当然,每个老师的重点势必会不一样,所以该内容仅供参考,具体重点还是以自己老师为准。 此外,文中...
含有2020年信息检索导论期末考试试题,2017信息检索导论作业及答案2016春国科大现代信息检索何苯期末试题(1),信息检索荷苯2015,信息检索荷苯2016,信息检索王斌2012 一、 选择题(单选, 每题 2 分,共 20 分) 1....
信息检索导论王斌译第一章课后习题答案
现代信息检索导论_王斌译_课后习题答案
信息检索导论 2.pdf
第一章布尔检索习题 1-2考虑如下几篇文档:文档 1breakthrough drug for schizophrenia文档 2new schizophren
信息检索导论原作者提供答案
信息检索导论配书论文集
中国科学院大学信息检索导论(李波)期末考试试题
信息检索导论 中科院王斌老师ppt 可结合相关书籍进行学习
Introduction to Information__ Retrieval信息检索导论_引擎学习-课件信息检索 8.1 信息检索系统的评价 .8.2 标准测试集 .8.3 无序检索结果集合的评价 .8.4 有序检索结果的评价方法 .8.5 相关性判断 .8.6 系统质量及...
图 灵 计 算 机 科 学 丛 书信息检索导论人 民 邮 电 出 版 社北 京王 斌 译Christopher D. Manning[美][德]版 权 声 明I
2017年最新信息检索导论答案完整版,内容清晰,考试复习必备
现代信息检索导论复习要点
研究生课程打印店没有往年考题,我搜集了一部分希望能作为你复习的指导吧!
信息检索导论书本第一课的PPT(英文版)
现代信息检索导论 2013 王斌 计算所 全部课件
主要介绍信息检索及信息检索系统的基本概念、...主要内容包括信息检索模型、文本操作技术、文本索引和搜索技术、查询处理与Web检索技术、分布式信息检索、文本分类与聚类、信息过滤等,并给出Web信息检索的实现实例。
UCAS 信息检索导论大作业--新闻检索系统 目标:定向采集不少于4个中文社会新闻网站或频道,实现这些网站新闻信息的自动爬取、抽取、索引和检索。 具体要求: : 新闻网页数目不少于5万页,新闻信息能在一天之内...
信息检索导论相关 翻译资料